PRODUCTS
新製品情報

第1章 序章
この記事では、VarisciteのSystem on Modulesを使用して独自の機械学習(ML)
アプリケーションの開発を開始する方法を段階的に説明します。
NXP eIQ™ MLソフトウェア開発環境からMLアプリケーションを構築するための
開発ツール、ユーティリティ、およびライブラリのコレクションを備えた
Yocto LinuxBSPを使用してイメージを構築する方法、イメージを使用して
構築されたデフォルトの例を実行する方法、そして最後に、簡単なMLの例を
最初から作成する方法を示します。
1.1. eIQ™ 機械学習ソフトウェア開発環境の概要
eIQ™を使用すると、ユーザーは完全なシステムレベルのアプリケーションを
簡単に開発して、視覚、音声、時系列データなどに関連するMLの問題を
解決できます。 一般的な例としては、顔認識、ポーズ推定、ジェスチャ認識、
音声アクセントの解釈などがあります。eIQ™の最新のソフトウェアスタックには、
eIQ™ Toolkitと呼ばれるMLワークフローツールが含まれています。
このツールを使用して、MLの詳細を学習し、eIQ Portalを介して独自の
MLモデルをトレーニングできます。 また、推論エンジン、
ニューラルネットワークコンパイラ、およびTensorFlow Lite、
Arm NN、ONNX Runtime、PyTorch、OpenCV、DeepViewRTなどの最適化された
ライブラリのサポートを可能にするeIQ™ Inferenceも含まれています。
eIQ™の詳細については、次のWebサイトをご覧ください。
🔗 NXP eIQ™ ML ソフトウェア開発環境
1.2. 前提条件
1.2.1. サポートされているVariscite SoM
DART-MX8M-PLUSおよびVAR-SOM-MX8M-PLUSは、専用のAI/MLアクセラレータ
であるNeural Processing Unit(NPU)を含むNXP i.MX8MPlusプロセッサに
基づいています。NPUは、MLアプリケーションの推論プロセス中に高い
パフォーマンスを実現するのに役立ちます。
この記事では、i.MX8MPlusプロセッサに基づくモジュールに焦点を当てていますが、
NXP i.MX8およびi.MX8Mファミリに基づく他のモジュールもMLアプリケーションに
使用できます。 このような場合、推論プロセスにはNPUではなくGPUまたは
CPUが使用されます。
1.2.2. eIQ™を有効にしたYocto Linux BSP
eIQ™ Inferenceエンジンとライブラリを使用してイメージを構築するには:
1.
variwiki.comの適切な「ソースコードからYoctoをビルドする」ガイドの
セクション1と3に従って、ビルドホストをセットアップし、使用するSOMおよび
YoctoバージョンのYoctoソースを取得します。
…
$ repo init -u https://github.com/varigit/variscite-bsp-platform.git -b
$ repo sync -j$(nproc) ②
❶ 例:<tag_name> をfsl-hardknottに; <manifest_name> をimx-5.10.35-2.0.0-var01.xml に置き換えます。
❷ 「repo sync」手順が完了するまでに時間がかかるかも知れません。☕
2. 選択したモジュールのイメージを構築するための環境を準備します:
$ MACHINE=
❶ 例:<module_name> をimx8mp-var-dart に置き換えます。
3. imx-image-full イメージを使用して、eIQ™MLパッケージをビルドします:
$ bitbake imx-image-full ①
❶ コンピュータの仕様によっては、この手順が完了するまでに数時間かかる場合があります。 ☕
4. 全てのイメージをSDカードに書き込みます。
a. ビルドされたイメージは、次のフォルダーにあります:
${BUILD}/tmp/deploy/images/<module_name>
$ zcat imx-image-full-
❶ 例<module_name> をimx8mp-var-dart に、<x> を b に置き換えます
⚠️ ご注意: dmesg または lsblk コマンドを使用して、正しいSDカードデバイス名を確認してください。
第2章 eIQ™ 機械学習デフォルトアプリケーション
MLサブカテゴリの数が非常に多いため、この記事ではイメージ分類問題である
supervised learning サブカテゴリの例についてのみ説明します。 分類問題が
どのように機能するかを学ぶために、TensorFlowによって提供されるトレーニング
済みスターターモデルを使用するeIQ™の例と、Yocto LinuxBSPとともに構築された
TensorFlow Liteの推論エンジンを実行します。
2.1. TensorFlow Lite
IQ™で最も人気があり十分にサポートされている推論エンジンとライブラリは、
Googleが開発したTensorFlow Liteです。 TensorFlowは、ネットワーク
トレーニングと推論の両方に使用できる機械学習用の人気のあるオープンソース
プラットフォームですが、TensorFlow Liteはレイテンシが低くバイナリサイズが
小さい組み込みデバイスで、TensorFlowモデルから推論を変換して実行するために
特別に設計されたツールのセットです。
2.1.1 イメージ分類概要
イメージ分類は、スーパーバイズされた学習サブカテゴリからの分類問題であり、
ハードコードされたルールに依存することなく、イメージが何を表すかを
識別するために使用できます。これを機能させるには、さまざまなクラスの
イメージを認識するようにイメージ分類モデルをトレーニングする必要があります。
例えば、車両、人、信号機、果物や動物の種類など、多くのオブジェクトを
認識するようにモデルをトレーニングできます。
イメージ分類モデルをトレーニングするには、トレーニングにイメージと
それに関連するラベルを付ける必要があります。モデルがトレーニングを
受けたクラスのいずれかに新しいイメージが属するかどうかを効率的に
予測できるように、ラベルごとに数百または数千のイメージが必要です。
モデルが新しい入力イメージを予測するプロセスは推論と呼ばれます。
新しいモデルのトレーニングプロセスは、ニューラルネットワークの定義方法
やモデルのトレーニングに使用されるデータ量など、いくつかの側面に応じて
多くの時間がかかります。
この記事で使用されているモデルは、TensorFlowによって以前にトレーニング
およびテストされています。この記事の最初の章で説明したように、
NXP eIQ™ Portal を使用して、独自のMLモデルを作成、最適化、デバッグ、
変換、およびエクスポートすることもできます。
モデルへのデータ入力として新しいイメージを提供すると、トレーニングされた
各オブジェクトを表すイメージの確率が出力されます。表1に出力例を示します。
表1. 確率結果の例
| オブジェクト名(ラベル) | 確率 |
|---|---|
| Dog | 0.91 |
| Cat | 0.07 |
| Rabbit | 0.02 |
イメージ分類モデルには対応するラベルファイルが付属しています。
このファイルには、モデルがトレーニングされたオブジェクトのリストが含まれています
(例えば、次のソースコード例のtensorflow/lite/java/ovic/src/testdata/labels.txtを参照)。
出力の各番号はラベルファイルのラベルに対応しています。上記の例では、
出力をモデルがトレーニングされた3つのラベルに関連付けると、この場合の
イメージがDogを表す可能性が高くなります。
2.1.2. イメージ分類例
eIQ™パッケージで構築された完全なイメージは、C++で記述された
イメージ分類の例と、Pythonで記述された同様の例を提供します。
TensorFlowのC++ APIは、推論を実行する計算単位を選択するオプション
を提供しますが、Pythonバインディングはこのオプションを提供しないため、
Pythonで記述された例はNPUでのみ推論を実行します。
このセクションでは、C++で記述されたデフォルトの例を実行する方法に
ついて説明します。 次のセクションでは、Phytonで記述されたデフォルトの
例を実行する方法について説明します。ここでは、TensorFlow LiteのPython
バインディングを使用して例を最初から作成する方法を学習します。
C++の例には、トレーニング済みのスターターモデル、ラベルファイル、
および推論プロセスへの入力として使用されるイメージの例が既に
付属しています。以下の表2を参照してください。
表2. イメージ分類例詳細
| 名前の例 | 言語 | デフォルトモデル | デフォルトラベル | デフォルト入力 |
|---|---|---|---|---|
| label_image | C++/Python | mobilenet_v1_1.0_224_quant.tflite | labels.txt | grace_hopper.bmp |
• ボードを起動し、イメージ分類の例が配置されている次のフォルダに移動します:
$ cd /usr/bin/tensorflow-lite-
❶ 例:<version> を2.4.1 に置き換えます
• 異なるモデル/ラベル/イメージ入力データファイルを使用するには、次の引数を使用します:
$ ./label_image -m
引数が指定されていない場合、この例では表2のデフォルト引数を使用します。
C++ (CPU) での例
1. “-a”引数と“0”値を使用してラベルイメージ例を実行し、CPUで推論を実行します:
$ ./label_image -a 0
a. 成功した分類出力は、次のようになります:
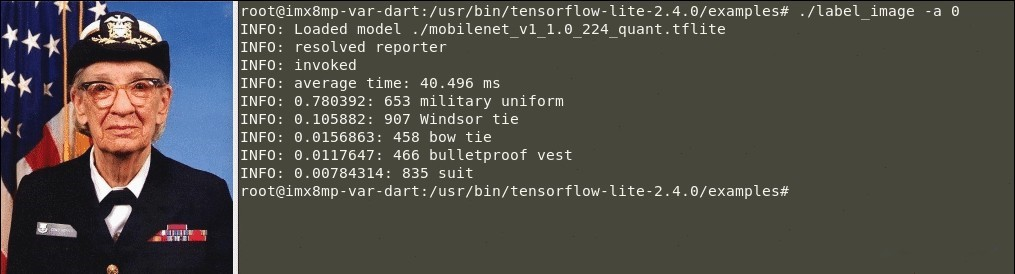
表1. TensorFlow Lite画像分類の例の実行(CPU推論)
🕒 CPUでの推論時間:40.496ミリ秒。
C++ (NPU)での例
1. “-a”引数と“1”値を使用してラベルイメージの例を実行し、CPUで推論を実行します:
$ ./label_image -a 1
a. 成功した分類出力は、次のようになります:
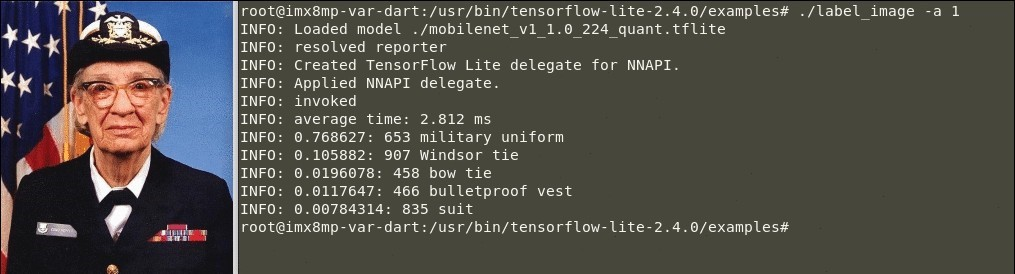
表2. TensorFlow Liteイメージ分類例の実行(NPU推論):
🕒 NPUでの推論時間:2.812ミリ秒
このメッセージは、推論がNPUで実行されていることを示しています:
“INFO: Applied NNAPI delegate.” 「情報:適用されたNNAPIデリゲート」
label_image例のソースコードは、tensorflow-imxリポジトリで入手できます:
🔗 tensorflow/examples/label_image/
第3章 eIQ™ MLアプリケーション開発
このセクションは、スターターモデル、ラベルファイル、およびデータ入力
としての画像を使用して、簡単な画像分類例を開発するためのステップバイ
ステップガイドです。 この例は、TensorFlow Lite Python APIを
使用してPythonで記述されています。
以下の手順は、モデルの入力サイズに応じて画像を開いてサイズを変更する
方法、NPUでの推論プロセスを通じて入力データとして画像を読み込む方法、
最後に出力を分析して確率結果を取得する方法を示しています。
この画像分類例のソースコードは、次の場所で入手できます:
🔗 The var-demos repository
上記のリポジトリには、次のような追加の例があります:
・画像ファイル、ビデオファイル、リアルタイムビデオストリーム分類
・画像ファイル、ビデオファイル、およびリアルタイムのビデオストリーム
検出(画像内のオブジェクトの位置とともに分類ラベルを返し、その周りに
長方形を描画します)
・ユーザーインターフェイスアプリケーションなど
3.1. ゼロからの画像分類
3.1.1. 初めに
1. ディレクトリを作成し、画像分類スターターモデルとデータ入力として
使用する無料の画像を取得します:
$ mkdir ~/example && cd ~/example
$ wget https://storage.googleapis.com/download.tensorflow.org/models/tflite/mobilenet_v1_1.0_224_quant_and
_labels.zip
$ wget https://raw.githubusercontent.com/varigit/var-demos/master/machine-learning-demos/tflite/classification/media/image.jpg
この画像は一例です。他の画像を自由に使用してください。
a. ディレクトリにモデルを抽出します:
$ unzip mobilenet_v1_1.0_224_quant_and_labels.zip
b. 冗長ファイルを削除します:
$ rm -rf __MACOSX/ mobilenet_v1_1.0_224_quant_and_labels.zip
2. .pyファイルを作成して、ソースコードの記述を開始します:
$ touch ~/example/image_classification.py
3. フォルダ構造は次のようになります:
.
├── image_classification.py
├── image.jpg
├── labels_mobilenet_quant_v1_224.txt
└── mobilenet_v1_1.0_224_quant.tflite
0 directories, 4 files
3.1.2. image_classification.pyを編集してソースコードを記述します
1. 先ず、Time、NumPy、Pillow、およびTensorFlow Liteライブラリを
インポートします:
1 from time import time
2
3 import numpy as np
4 from PIL import Image
5 from tflite_runtime.interpreter import Interpreter
2. 分類モデルのラベルファイルから行を開いて読み取ります:
6 with open('labels_mobilenet_quant_v1_224.txt') as f:
7 labels = f.read().splitlines()
3. インタープリタモジュールを使用して画像分類モデルをロードし、
そのテンソルを割り当てます:
8 interpreter = tf.Interpreter(model_path="mobilenet_v1_1.0_224_quant.tflite")
9 interpreter.allocate_tensors()
4. 画像分類モデルの入力テンソルと出力テンソルから詳細を取得します:
10 input_details = interpreter.get_input_details()
11 output_details = interpreter.get_output_details()
5. 画像を開き、モデルの入力サイズに応じてサイズを変更します:
12 with Image.open("image.jpg") as im:
13 _, height, width, _ = input_details[0]['shape']
14 image = im.resize((width, height))
15 image = np.expand_dims(image, axis=0)
6. サイズ変更された画像をNPUへのデータ入力としてロードするには、
入力テンソル(tensor)を設定します:
16 interpreter.set_tensor(input_details[0]['index'], image)
7. invokeメソッドを呼び出して、NPUで推論を開始します:
17 interpreter.invoke() ①
❶invokeメソッドの最初の呼び出しは、初期化手順のために通常よりも時間
18
19 start = time()
20 interpreter.invoke() ②
21 final = time()
がかかります。
❷NPUが推論を実行するのにかかる実際の時間を取得するには、invokeメソッドを
再度呼び出します。
初期化ステップは、ウォームアップフェーズとも呼ばれます。 これらは、
アプリケーションの開始時に1回だけ必要です。
8. NPUで推論を実行した後、出力の詳細を取得します。
22 output_details = interpreter.get_output_details()[0]
9. 画像分類概要セクション で説明されているように、最も関連性の
高い3つの確率を取得します:
23 output = np.squeeze(interpreter.get_tensor(output_details['index']))
25 results = output.argsort()[-3:][::-1]
10. ラベルとその確率を印刷します:
26 for i in results:
27 score = float(output[i] / 255.0)
28 print("[{:.2%}]: {}".format(score, labels[i]))
29
11. そして最後に推論時間を印刷します:
30 print("INFERENCE TIME: {:.6f} seconds".format(final-start))
3.1.3 選択したモジュールで例をテストします
1. サンプルフォルダをターゲットボードにコピーします:
$ scp -r ~/example root@
a. ボード上で、次のコマンドを実行します:
# cd /home/root/example
# python3 image_classification.py
b. 成功した分類の出力は次のようになります:
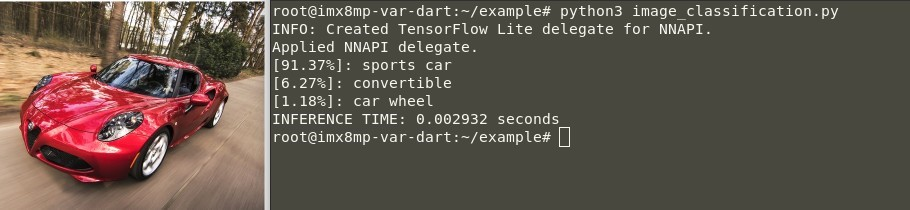
図3.TensorFlow Lite画像分類の入力例(NPU推論)
🕒 NPUでの推論時間:2.9ミリ秒
ご覧のとおり、モデルは画像がスポーツカーを表す可能性が高い
(91.37%)と予測しています。
この例は、画像分類問題に関連するアプリケーションのベースとして
さらに使用できます。 例えば、上記のvar-demosリポジトリで
行われているように、OpenCVとGStreamerを使用して、画像ファイル
入力の代わりに、カメラからのビデオファイルまたはライブビデオ
ストリームを使用するようにソースコードを変更できます。
半導体流通市場も大きく広がっていき、さらに成長を続けています。
自分の能力を存分に発揮したいという方、
エレクトロニクス分野で活躍したい方 企業家・事業化精神に
あふれた方、想いにお応えできるフィールドがあります。
製品の他にも、サービスに関する事、PRに関するご質問等、
承っております。みなさまからのお問合せについては、
以下の窓口よりお受けしております。
お気軽にご連絡ください。
本社
〒105-6235 東京都港区愛宕2-5-1
愛宕グリーンヒルズMORIタワー35F
TEL : 03-5425-1531 FAX : 03-5539-4841
関西営業所
〒532-0004 大阪市淀川区西宮原1-5-28
新大阪テラサキ第3ビル6F
TEL : 06-7668-5500 FAX : 06-7668-5501
© 2026 Arrow Electronics Japan KK. All Rights Reserved